

当对话型 AI 办事于数十亿用户时,咱们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。
对话型 AI 系统的部署范围已达到前所未有的量级,每天贬责数十亿次用户交互。然则,绝大大宗现存研究都聚焦于用户「说了什么」,关于用户在对话中「想了什么」这一更深层的维度,还是一派险些未被探索的空缺。
不管是 WildChat、LMSYS-Chat-1M 这类对话数据集,照旧络续的方法和测试基准,它们都将对话文本视为独一可不雅测单位 —— 用户未说出口的动机、轨则、立场期许以及对恢复的果真评价,则被默许丢弃。事实上,由于「最少死力原则」(principle of least effort) 与语用层面的压力,用户写下的领导与他们脑中的果真意图之间存在自然的信息耗费:理论抒发高效、外交多礼、主见导向,却并非里面热诚情状的完好呈现。
当今主流的对皆方法大多依赖偏好评分、点赞点踩或基于音问文本的反馈,这些信号难以分辨「哪一部分回答让用户不激昂」「为什么不激昂」,也无法揭示用户在多轮交互中如安在内心演进我方的主见。因此,一个要津问题浮出水面:
如安在果真的东说念主机对话中,系统性地捕捉用户那些「未言明的念念考」,并将其当作新的数据模态用于锻练和评估 AI 助手?
近日,一篇来自 JHU、MIT 与 Google Research 的研究,为这一问题提供了一种解法。
他们建议了 ThoughtTrace—— 首个将果真多轮东说念主机对话与用户「自我求教的念念考」配对的大范围数据集。这里所说的念念考分为两类:用户发送领导前的 reasons(动机、主见、落魄文、内容与立场期许等),以及用户读到 AI 恢复后的 reactions(激昂、对内容、立场或范围的具体动怒等)。这些第一东说念主称领略陈迹捕捉了每一次对话背后的荫藏领略层,将「可不雅测的语句」与「果真的用户意图」之间的范围系统性地填补起来。
在这一框架下,研究东说念主员构建了一个具有以下范围的语料库:
1,058 名用户
2,155 段多轮对话
17,058 次交互轮次
10,174 条念念考标注
笼罩 20 个不同的话语模子(包括 GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro Preview 等前沿模子,以及几许开源轻量模子)
基于这一数据,作家评释:念念考不祥将下一条用户音问算计的语义相似度从 21.6 擢升至 30.6(相对擢升 41.7%),并将基于 Arena-Hard 的对皆胜率擢升 25.6%。这为后续 RL、DPO 等锻练范式提供了一种全新的、ground-truth 级别的监督信号。

论文标题:ThoughtTrace: Understanding User Thoughts in Real-World LLM Interactions
论文一语气:https://arxiv.org/abs/2605.20087
开运体育中国app官方手机版方法概览
为了让用户在当然对话中淳厚地外化我方的念念考,作家通过 Prolific 招募参与者,并商量了一套四步的网罗经过:
知情应许:参与者签署知情应许书,明确自觉参与与可随时退出的权力。
教程与检修:通过教训式教程学习聊天界面、标注念念考,并通过浅显的清爽检修后才参预正经门径。
带念念考标注的对话:参与者自行设定两个怒放式任务,开脱地与 AI 多轮疏通;在每条用户音问上标注 reason、在每条 AI 恢复上标注 reaction。用户不错随时开启新对话或达成任务,且标注对 AI 皆备不可见。
任务后探问:完成任务后形容我方实质完成了什么、对 AI 有什么期许,并填写涵盖年级、性别、老师、管事、AI 使用频率与主要用途的问卷。
每条 ThoughtTrace 记载对应一段完好的对话,按技艺戳保存所灵验户音问、AI 恢复以及附着其上的念念考。其中 reason 来自 7 种类型之一,reaction 来自 5 种类型之一,每条念念考都带有我方的时刻戳与文本内容。
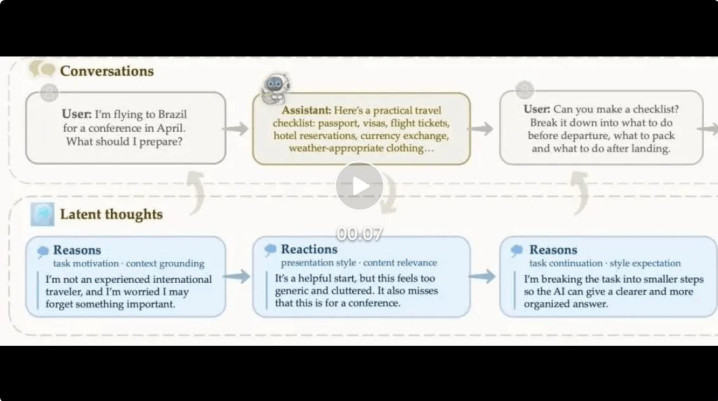
视频一语气:https://mp.weixin.qq.com/s/fxYJRiIsVNbVHO3HMZ9TEQ?click_id=18
数据特点
作家从两个维度描画 ThoughtTrace:对话层面和念念考层面。
对话层面有三大特点:
代表性的用户群:笼罩 18 至 65+ 各年级段、多种老师水平与劳开拔份,AI 使用频率从「从未」到「逐日屡次」,适合络续 AI 用户的东说念主口画像。
长程、多元的对话:ThoughtTrace 的对话中位数为 8 轮,而 WildChat 与 LMSYS-Chat-1M 都是 2 轮;话题散布畸形 7 个大类、36 个细分子主题,莫得单一类别占主导。
任务蔓延主导:57.0% 的用户音问属于「在已有任务上膨胀、长远、迭代」,远超新央求 (12.5%)、重试 (2.9%) 和变体 (2.3%),开云足球世界杯官方手机APP下载且这种蔓延模式随对话阐述而愈发显赫。
念念考层面则呈现四个要津性质:
念念考与音问显赫不同:镶嵌空间可视化与基于 LLM 的语义笼罩打分均透露,用户音问对其背后 reason 的笼罩度仅 3.22 (1–5 分制),对前一轮 reaction 的笼罩度仅 2.00—— 对话文本远不成完好复现用户的内心行动。
念念考对前沿 LLM 而言难以推断:让 GPT-5.4、Gemini 3.1 Pro Preview、Claude Opus 4.6 从对话落魄文中推测用户的 reason 与 reaction,三模子平均得分仅为 2.93 和 2.54,介于「少量重复」与「部分重复」之间。
念念考内容高度多元:7 种 reason 涵盖 Task Motivation & Goal (36.9%)、Task Continuation (21.4%)、Context Grounding & Constraints (13.1%)、Content Expectation (11.5%)、Task Reorientation (11.1%)、Style Expectation (5.0%) 和 Social and Others (1.0%);5 种 reaction 包括 Explicit Affirmation (72.2%)、Content Relevance (11.9%)、Presentation Style (6.4%)、Scope Fit (6.1%)、Partial Satisfaction (3.4%)。
念念考随对话阶段动态变化:Task Motivation 主导早期,Task Continuation 在中后期占主导;Explicit Affirmation 从早期 67% 上涨至晚期 79%,反应对话向令东说念主激昂的回答治理。这种动态闲适于话题或长度,仅与对话阶段和多轮络续络续。
实验遵守
为了考证这些「内心念念考」是否真能用于下贱建模,作家商量了两组要津实验,辨别考察 thoughts 在推理时和锻练时的价值。

实验一:Thoughts Predict User Behavior
让 LLM 算计用户的下一条音问 —— 辨别在「仅有对话历史」与「历史 + 用户念念考标注」两种条目下,评估三个前沿模子,并使用当场抽取的另一个模子当作 LLM judge 评判 0–100 分的语义相似度。
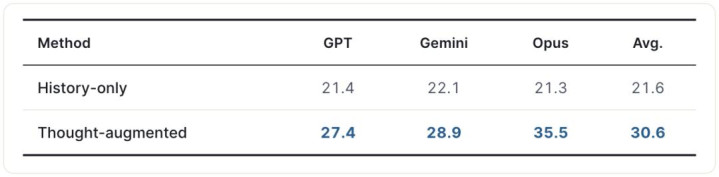
只是向模子提供用户的内心念念考,平均算计分数从 21.6 跃升到 30.6,相对擢升 41.7%。Opus 4.6 的擢升尤为显赫,单独擢升 14.2 个点。这确认 ThoughtTrace 中的 reason 与 reaction 提供了对话历史所不具备的、不祥预示用户改日行动的可试验信号 —— 这一发现对构建高保真用户模拟器、面向用户主动协助的智能体均有径直价值。
实验二:Thoughts Improve Model Alignment
作家径直应用 ThoughtTrace 的 reaction 标签定位「用户实质不激昂的恢复」,再用对应的念念考内容指引模子重写,酿成 thought-guided rewrites;将其与原始音问配对,在 Qwen3.5-4B 上进行 DPO 锻练,于 Arena-Hard 上评估。
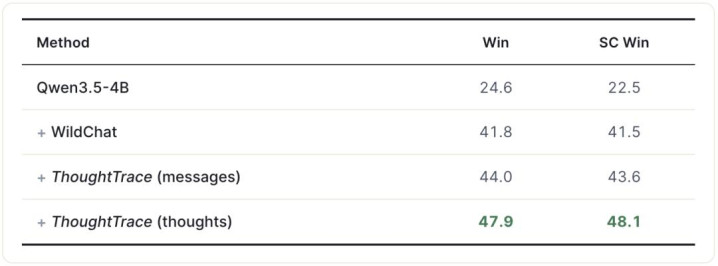
相较基础模子,念念考教训版块在立场箝制胜率上擢升 25.6%;
相较 WildChat 基线,擢升 6.6%;
相似在 ThoughtTrace 上,念念考教训比音问教训高 4.5%,标明念念考承载着比音问更丰富的动怒与修正信号。
更值得眷注的是,念念考能从团结批对话中识别出 1,000 条不激昂实例,而仅依赖音问只可挖出 450 条,前者是后者的 2.2 倍,评释了念念考自然提供了更密集的监督。这意味着 thoughts 不仅告诉咱们「哪一条回答用户不激昂」,还径直确认「应当怎么修正」,把响应识别和响应修正两件事斡旋进了团结条监督信号。
结语
作家将 thoughts 定位为东说念主机交互研究的一种新数据模态:它捕捉用户的潜在领略,难以从语句中收复,畸形多种内容花式,并随对话阶段动态变化。不管是用户行动算计、模子对皆,照旧改日的奖励建模、On-Policy Distillation 等在线学习范式,念念考都提供了音问文本所无法替代的细粒度信号。
ThoughtTrace 由此掀开了三条新的研究场所:(1)用户建模 —— 系统研究东说念主机交互中的动态热诚过程;(2)模子锻练 —— 把念念考当作新的监督信号,用于锻练信得过清爽用户潜在主见与偏好的助手;(3)评估 —— 构建以念念考为中心的基准,把评估从名义语句鼓励到潜介意图与主不雅体验。
正如论文所言,ThoughtTrace 将用户念念考诱惑为研究东说念主机交互背后领略能源学的一种基础信号,也为构建信得过清爽用户「潜在主见、偏好与需求」的下一代 AI 助手开云IOS/Android通用版/手机app,铺设了一条新的研究旅途。