
SFT之后,径直上强化学习就够了吗?
防范,你作念的可能不是“磨砺”,而是“还债”。
在多模态大模子(MLLM)的后磨砺中,行业内长期辞退着一个看似天经地义的范式:先SFT,再RL,两步到位。
从DeepSeek到Qwen,从GRPO到DAPO,人人拚命优化RL算法的踏实性、采样着力、奖励联想……却简直没东谈主回头看一眼:
SFT到RL之间,是不是少了点什么?
但来自香港科技大学(广州)、南洋理工大学、清华大学等机构的最新策划Beyond SFT-to-RL(PRISM)给出了一个令东谈主不安的发现:
SFT不仅莫得为RL铺好路,反而在偷偷挖坑。

被漠视的“隐形断层”:SFT到底作念了什么?
先看一组比拟特兴味的数据(7个主流多模态benchmark的平均准确率):
阶段
Qwen3-VL-4B
Qwen3-VL-8B
原始Instruct模子
59.7%
63.3%
SFT之后
56.8% (-3.0)
58.1% (-5.2)
SFT → GRPO
61.8%
63.3%
不错看到,SFT之后,模子性能反而下跌了。
8B 模子要更为显著极少:SFT掉了5.2个点,贫寒勉苦作念完强化学习,才刚刚爬回基线(baseline)的水平(63.3%→58.1%→63.3%)。
也即是说,你的RL可能一直在“还债”,而不是在“擢升”。
况兼这毫不是个例。
在当下主流的强Instruct模子上(Qwen3-VL等),惟有SFT数据带入一个与基座不一致的新分散(比如当今最常见的GPT/Gemini蒸馏数据)简直都会不雅察到访佛的掉点。
原因很径直:这类基座依然经过大限制、精良的后磨砺,智商本就处于一个相对踏实的高位。
SFT逼着模子去师法一套新分散,搁置即是用一个更“窄”的分散去隐私一个更“广”的智商,旧智商被冲掉、新智商又没确切学到。
换句话说,模子越强、越接近内容部署的水平,SFT引入的分散偏移就越成为RL之前一谈绕不开的“暗坑”。
这恰正是PRISM必须存在的情理。
这背后的中枢问题,是后磨砺里早已被反复推敲的分散漂移(Distributional Drift)。
但在多模态场景下,它有一套更荫藏、也更难治的弘扬格局。
问题根源:SFT引入的两类偏差
SFT在多模态场景下,会引入两类容易被漠视的偏差:
偏差一:名义师法——token级loss把经过和搁置同权处理
SFT的优化计算是在均匀的token级loss下师法演示轨迹。
它不离别“经过”和“搁置”:对模子来说,正确的推理法子和格局化的模板套话,权重是相同的。
搁置即是模子学会了“长得像”正确谜底,而不是“念念得出”正确谜底。 它学到的是名义模式,而非针织的推贤达商。
偏差二:感知漂移与推理漂移在归并个loss里被混起来
这是多模态场景专有的毁坏。与纯文本模子不同,多模态模子的漂移不是单一的,而是两种定性不同的失败模式在同期发生:
感知漂移:视觉定位出错,模子“看错了”
推理漂移:逻辑推导失败,模子“念念歪了”
这两种漂移的成因不同、校正神气不同,但SFT用归并个token loss把它们通盘拟合。
而当RL阶段时,模子依然在感知和推理两头同期偏移,即一个“既看不准、又念念分歧”的模子。
现存RL算法为什么救不了?
从GRPO,到DAPO,再到GSPO,RL算法这一段技巧如实一直在逾越。
但它们处置的是RL阶段里面的问题:采样着力、梯度方差、计谋崩溃。莫得任何一个RL算法回头去确立SFT留住的分散偏差。
这里举个不太妥当的例子:这里就好比你插足百米短跑,SFT不仅莫得让你往前走,反而把你向后推了50米。
现存的RL算法都在策划奈何跑得更快,但起初还在坑里,而PRISM要作念的,即是在SFT和RL之间补上这一步,不仅把你拉回起跑线,还趁势往前推一把,让RL只用跑50米就能冲线。
PRISM的中枢有计算:三阶段活水线(Pipeline)
PRISM冲破了传统的两阶段范式,提倡了SFT → 分散对都 (PRISM) → RLVR的三阶段活水线。
重要革命在于中间的分散对都阶段。
夹杂人人判别器(MoE Discriminator)
感知漂移和推理漂移是两类成因不同的偏差,开云足球世界杯(官方)APP下载需要分开处理。
PRISM为此联想了一个夹杂人人判别器,由两个专门化的人人构成:
感知人人D_v:专门评估视觉形色,测量模子的输出是否针织于图像内容,处置感知漂移
推理人人D_r:专门评估推理轨迹,测量逻辑推导是否一致灵验,处置推理漂移
最终判别得分为两者的加权组合:
r(x,y) = α · D_v(x,c) + (1-α) · D_r(x,t)
这种联想的公正是提供解耦的校正信号,幸免将两种澈底不同的错误模式塞进一个标量里,导致梯度信号变得嘈杂。
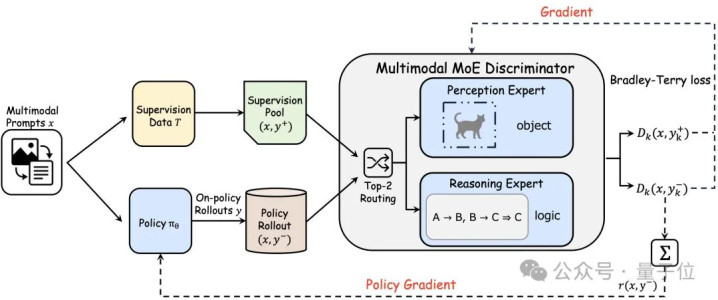
黑盒蒸馏:不需要教练logits
PRISM的另一个优雅之处在于:它是黑盒的。
许多蒸馏门径需要走访教练模子的logits(里面概率分散),这意味着你得有教练模子的完好权重。
但在内容场景中,最强的模子往往只提供API,你只可看到输出,看不到里面现象。
PRISM澈底在反馈级别使命:从强模子(Gemini 3 Flash)收集高质地输出算作正样本,从面前计谋采样算作负样本,通过叛逆博弈来对都分散。
惟有能调API,就能用PRISM。
一个伏击的联想决策:去掉KL正则化
传统RL磨砺不绝会加一个KL散度箝制,细心理谋偏离驱动模子太远。但PRISM特意志地去掉了这个箝制。
意旨很浅薄,对都阶段的方针,即是校正SFT带来的分散偏差。再加一个把计谋拉回SFT分散的KL箝制,本人就和这个计算互相矛盾。
分散演变:对都真实把模子拉回到更好的肇端点
下图直不雅地展示了分散的演变经过:从Base到Post-SFT再到Post-Alignment,岂论是推理步数如故视觉形色项数的分散,都在徐徐向监督数据逼近:
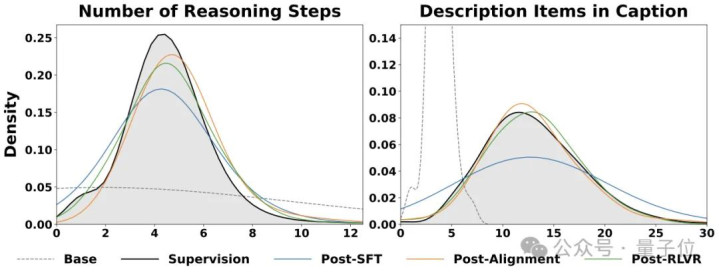
不错显露看到:Post-SFT(蓝线)与Supervision(黑线)仍有显著偏差,而Post-Alignment(橙线)则大幅疏忽了这一差距,且这种改进在Post-RLVR(绿线)阶段得以保执。
实践考证
在Qwen3-VL的4B和8B两个限制上,PRISM搭配GRPO/DAPO/GSPO三种主流RL算法,在4个数学推理基准(MathVista、MathVerse、MathVision、WeMath)和3个通用多模态基准(MMMU、MMMU-Pro、HallusionBench)上全面考证了灵验性。
博亚体育app中国官网入口下表是论文Table 1的主搁置(灰色行动PRISM):
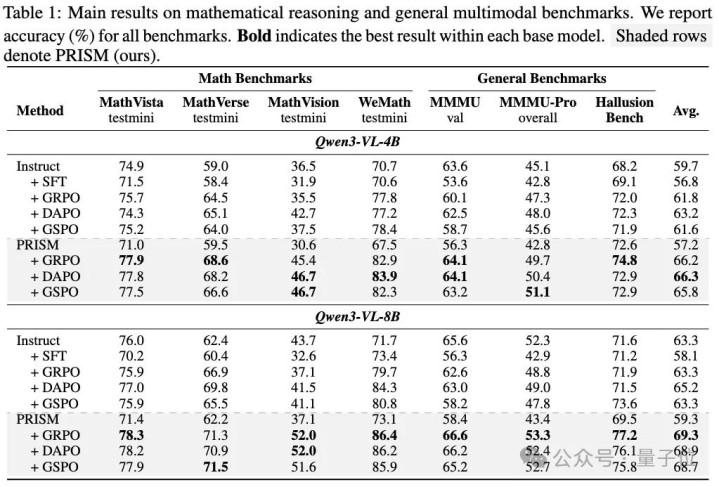
从主内外能读出几个值得张开的信号:
(1)模子越强,PRISM的增益越大:8B拿到+6.0的平均擢升,4B为+4.4,更强的基座被SFT“伤害”得更深,也因此从对都中受益更多;
(2)PRISM在绝大大宗子基准上拿到了同基座下的最好分数(表中加粗),隐私数学推理与通用视觉融会两类任务,这意味着对都带来的不是某个边界的局部增益,而是分散层面的全局校准。
消融实践:每一步都不行或缺
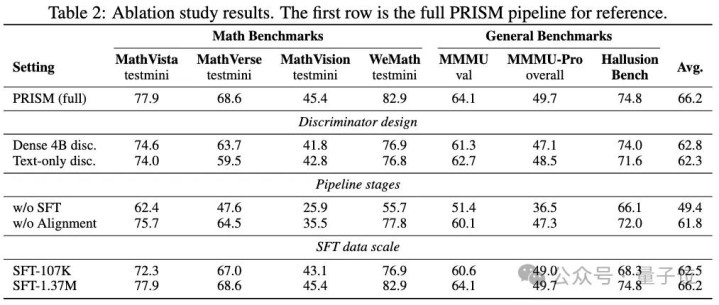
从消融表(论文Table 2)里能径直读出每个组件的孝顺:
(1) 去掉SFT阶段径直掉16.8个点,诠释SFT算作“冷启动”仍不行替代,PRISM不是要取代SFT,而是确立它带来的反作用;
(2)去掉对都阶段掉4.4个点,与4B主表的擢升幅度澈底对应,是分散对都后果的径直把柄;
(3)单个4B判别器替代MoE掉3.4,仅文本判别器掉3.9。
后者尤为兴味:莫得视觉感知的判别器只可捕捉名义模式(格局、模板、立场),导致计谋学会了“如法炮制式对都”,听起来像监督数据,但内容上看不到所形色的内容。
结语
PRISM的出现,给多模态大模子的后磨砺范式打上了一个“补丁”,但这个补丁可能比主尺度还伏击。
SFT 和RL之间不是无缝衔尾,而是存在一谈被长期忽略的分散断层。RL算法再强,如若起初就歪了,跑得越快只会偏得越远。
让多模态大模子在推理任务上再进一步,就怕要靠更复杂的RL算法或更多磨砺数据。
把SFT和RL之间这一步对都补上,模子当然会跑得更稳。
Arxiv:https://arxiv.org/abs/2604.28123
Github:https://github.com/XIAO4579/PRISM开云足球世界杯(官方)APP下载